An Empirical Analysis of Information Encoded in Disentangled Neural Speaker Representations
| Raghuveer Peri, Haoqi Li, Krishna Somandepalli, Arindam Jati, Shrikanth Narayanan |
|---|
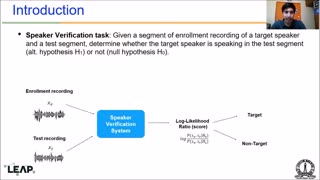
The primary characteristic of robust speaker representations is that they are invariant to factors of variability not related to speaker identity. Disentanglement of speaker representations is one of the techniques used to improve robustness of speaker representations to both intrinsic factors that are acquired during speech production (e.g., emotion, lexical content) and extrinsic factors that are acquired during signal capture (e.g., channel, noise). Disentanglement in neural speaker representations can be achieved either in a supervised fashion with annotations of the nuisance factors (factors not related to speaker identity) or in an unsupervised fashion without labels of the factors to be removed. In either case it is important to understand the extent to which the various factors of variability are entangled in the representations. In this work, we examine speaker representations with and without unsupervised disentanglement for the amount of information they capture related to a suite of factors. Using classification experiments we provide empirical evidence that disentanglement reduces the information with respect to nuisance factors from speaker representations, while retaining speaker information. This is further validated by speaker verification experiments on the VOiCES corpus in several challenging acoustic conditions. We also show improved robustness in speaker verification tasks using data augmentation during training of disentangled speaker embeddings. Finally, based on our findings, we provide insights into the factors that can be effectively separated using the unsupervised disentanglement technique and discuss potential future directions.