Advances in Speaker Recognition for Telephone and Audio-Visual Data: the JHU-MIT Submission for NIST SRE19
| Jesus Antonio Villalba Lopez, Daniel Garcia-Romero, Nanxin Chen, Gregory Sell, Jonas Borgstrom, Alan McCree, Leibny Paola Garcia Perera, Saurabh Kataria, Phani Sankar Nidadavolu, Pedro Torres-Carrasquiilo, Najim Dehak |
|---|
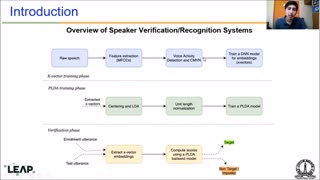
We present a condensed description of the joint effort of JHU-CLSP, JHU-HLTCOE and for NIST SRE19. NIST SRE19 consisted of a Tunisian Arabic Telephone Speech challenge (CTS) and an audio-visual (AV) evaluation based on Internet video content. The audio-visual evaluation included the regular audio condition but also novel visual (face recognition) and multi-modal conditions. For CTS and AV-audio conditions, successful systems were based on x-Vector embeddings with very deep encoder networks, i.e, 2D residual networks (ResNet34) and Factorized TDNN (F-TDNN). For CTS, PLDA back-end domain-adapted using SRE18 eval labeled data provided significant gains w.r.t. NIST SRE18 results. For AV-audio, cosine scoring with x-Vector fine-tuned to full-length recordings outperformed PLDA based systems. In CTS, the best fusion attained EER=2.19% and Cprimary=0.205, which are around 50% and 30% better than SRE18 CTS results respectively. The best single system was HLTCOE wide ResNet with EER=2.68% and Cprimary=0.258. In AV-audio, our primary fusion attained EER=1.48% and Cprimary=0.087, which was just slightly better than the best single system (EER=1.78%, Cprimary=0.101). For the AV-video condition, our systems were based on pre-trained face detectors--MT-CNN and RetinaFace--and face recognition embeddings--ResNets trained with additive angular margin softmax. We focused on selecting the best strategies to select the enrollment faces and how to cluster and combine the embeddings of the faces of the multiple subjects in the test recording. Our primary fusion attained EER=1.87% and Cprimary=0.052. For the multi-modal condition, we just added the calibrated scores of the individual audio and video systems. Thus, we assumed complete independence between audio and video modalities. The multi-modal fusion provided impressive improvement with EER=0.44% and Cprimary=0.018.