Information Preservation Pooling for Speaker Embedding
| Min Hyun Han, Woo Hyun Kang, Sung Hwan Mun, Nam Soo Kim |
|---|
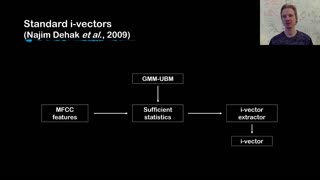
Many recent studies on speaker embedding focused on the pooling technique. In the task of speaker recognition, pooling plays an important role of summarizing inputs with variable length into a fixed dimensional output. One of the most popular pooling method for text-independent speaker verification system is attention based pooling method which utilizes an attention mechanism to give different weights to each frame. Utterance-level features are generated by computing weighted means and standard deviations of frame-level features. However, useful information in frame-level features can be compromised during the pooling step. In this paper, we propose a information preservation pooling method that exploits a mutual information neural estimator to preserve local information in frame-level features during the pooling step. We conducted the evaluation on VoxCeleb datasets, which shows that the proposed method reduces equal error rate from the conventional method by 14.6%