WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution
(3 minutes introduction)
| Kexun Zhang (Zhejiang University, China), Yi Ren (Zhejiang University, China), Changliang Xu (Xinhua News Agency, China), Zhou Zhao (Zhejiang University, China) |
|---|
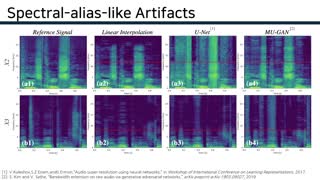
Audio super-resolution is the task of constructing a high-resolution (HR) audio from a low-resolution (LR) audio by adding the missing band. Previous methods based on convolutional neural networks and mean squared error training objective have relatively low performance, while adversarial generative models are difficult to train and tune. Recently, normalizing flow has attracted a lot of attention for its high performance, simple training and fast inference. In this paper, we propose WSRGlow, a Glow-based waveform generative model to perform audio super-resolution. Specifically, 1) we integrate WaveNet and Glow to directly maximize the exact likelihood of the target HR audio conditioned on LR information; and 2) to exploit the audio information from low-resolution audio, we propose an LR audio encoder and an STFT encoder, which encode the LR information from the time domain and frequency domain respectively. The experimental results show that the proposed model is easier to train and outperforms the previous works in terms of both objective and perceptual quality. WSRGlow is also the first model to produce 48kHz waveforms from 12kHz LR audio. Audio samples are publicly available.