End-to-end audio-visual speech recognition for overlapping speech}
(3 minutes introduction)
| Richard Rose (Google, USA), Olivier Siohan (Google, USA), Anshuman Tripathi (Google, USA), Otavio Braga (Google, USA) |
|---|
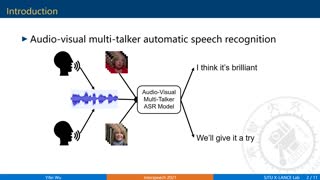
This paper investigates an end-to-end audio-visual (A/V) modeling approach for transcribing utterances in scenarios where there are overlapping speech utterances from multiple talkers. It assumes that overlapping audio signals and video signals in the form of mouth-tracks aligned with speech are available for overlapping talkers. The approach builds on previous work in audio-only multi-talker ASR. In that work, a conventional recurrent neural network transducer (RNN-T) architecture was extended to include a masking model for separation of encoded audio features and multiple label encoders to encode transcripts from overlapping speakers. It is shown here that incorporating an attention weighted combination of visual features in A/V multi-talker RNN-T models significantly improves speaker disambiguation in ASR on overlapping speech relative to audio-only performance. The A/V multi-talker ASR systems described here are trained and evaluated on a two speaker A/V overlapping speech dataset created from YouTube videos. A 17% reduction in WER was observed for A/V multi-talker models relative to audio-only multi-talker models.