Dynamically Adaptive Machine Speech Chain Inference for TTS in Noisy Environment: Listen and Speak Louder
(3 minutes introduction)
| Sashi Novitasari (NAIST, Japan), Sakriani Sakti (NAIST, Japan), Satoshi Nakamura (NAIST, Japan) |
|---|
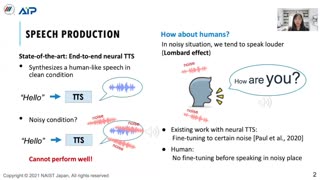
Although machine speech chains were originally proposed to mimic a closed-loop human speech chain mechanism with auditory feedback, the existing machine speech chains are only utilized as a semi-supervised learning method that allows automatic speech recognition (ASR) and text-to-speech synthesis systems (TTS) to support each other given unpaired data. During inference, however, ASR and TTS are still performed separately. This paper focuses on machine speech chain inferences in a noisy environment. In human communication, speakers tend to talk more loudly in noisy environments, a phenomenon known as the Lombard effect. Simulating the Lombard effect, we implement a machine speech chain that enables TTS to speak louder in a noisy condition given auditory feedback. The auditory feedback includes speech-to-noise ratio prediction and ASR loss as a speech intelligibility measurement. To the best of our knowledge, this is the first deep learning framework that mimics human speech perception and production behaviors in a noisy environment.