CoVoST 2 and Massively Multilingual Speech Translation
(3 minutes introduction)
| Changhan Wang (Facebook, USA), Anne Wu (Facebook, USA), Jiatao Gu (Facebook, USA), Juan Pino (Facebook, USA) |
|---|
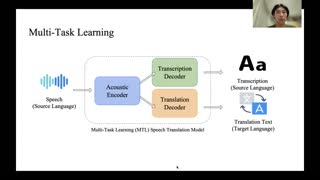
Speech translation (ST) is an increasingly popular topic of research, partly due to the development of benchmark datasets. Nevertheless, current datasets cover a limited number of languages. With the aim to foster research into massive multilingual ST and ST for low resource languages, we release CoVoST 2, a large-scale multilingual ST corpus covering translations from 21 languages into English and from English into 15 languages. This represents the largest open dataset available to date for volume and language coverage. Data checks provide evidence about the data quality. We provide extensive speech recognition (ASR), machine translation (MT) and ST baselines. We demonstrate the value of CoVoST 2 for multilingual ST research by leveraging it in 4 investigations: simplify multilingual training by removing ASR pretraining, study multilingual model scaling properties and investigate zero-shot and transfer learning capabilities of models trained on CoVoST 2.