Configurable Privacy-Preserving Automatic Speech Recognition
(3 minutes introduction)
| Ranya Aloufi (Imperial College London, UK), Hamed Haddadi (Imperial College London, UK), David Boyle (Imperial College London, UK) |
|---|
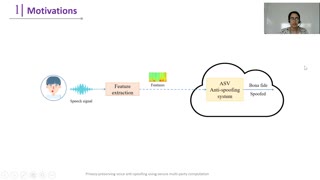
Voice assistive technologies have given rise to far-reaching privacy and security concerns. In this paper we investigate whether modular automatic speech recognition (ASR) can improve privacy in voice assistive systems by combining independently trained separation, recognition, and discretization modules to design configurable privacy-preserving ASR systems. We evaluate privacy concerns and the effects of applying various state-of-the-art techniques at each stage of the system, and report results using task-specific metrics (i.e., WER, ABX, and accuracy). We show that overlapping speech inputs to ASR systems present further privacy concerns, and how these may be mitigated using speech separation and optimization techniques. Our discretization module is shown to minimize paralinguistics privacy leakage from ASR acoustic models to levels commensurate with random guessing. We show that voice privacy can be configurable, and argue this presents new opportunities for privacy-preserving applications incorporating ASR.